__ ___ _ _ _ ____ / / ___ / _ \__ _ _ _ ___ __| |_ _ | || ||___ \ / / / _ \ / /_)/ _` | | | / __| / _` | | | | | || |_ __) | / /__| __/ / ___/ (_| | |_| \__ \ | (_| | |_| | |__ _/ __/ \____/\___| \/ \__,_|\__, |___/ \__,_|\__,_| |_||_____| |___/
$> ls -l
-rwrw-rw- 1 db0 db0 62.1 Ko 2015-03-30 19:37 Impatient C
-rwrw-rw- 1 db0 db0 3.5 Ko 2015-03-30 19:37 Impatient SCM
-rwrw-rw- 1 db0 db0 3.0 Ko 2015-03-30 19:37 Impatient Emacs
-rwrw-rw- 1 db0 db0 2.4 Ko 2015-03-30 19:37 Impatient Man Pages
-rwrw-rw- 1 db0 db0 10.5 Ko 2015-03-30 19:37 Impatient Perl
-rwrw-rw- 1 db0 db0 17.3 Ko 2015-03-30 19:37 Impatient Python
-rwrw-rw- 1 db0 db0 13.6 Ko 2015-03-30 19:37 Impatient Shell Debutant
-rwrw-rw- 1 db0 db0 16.4 Ko 2015-03-30 19:37 Impatient Shell Script
-rwrw-rw- 1 db0 db0 3.4 Ko 2015-03-30 19:37 Impatient Shell
-rwrw-rw- 1 db0 db0 1.8 Ko 2015-03-30 19:37 Impatient Vim
Impatient - C
Ce cours se veut Être utilisable comme une fiche de rÃĐfÃĐrence (des "rappels" ou un "support de cours") mais aussi permettre aux dÃĐbutants d'apprendre.
C'est pour cette raison que l'on y trouve des informations explicatives aux dÃĐbutants mÃĐlangÃĐes à des indications plus avancÃĐes (cachÃĐes, il faut cliquer sur "details" pour les voir).
J'ai conscience qu'il est difficile de satisfaire deux publics diffÃĐrents avec un mÊme texte, c'est pourquoi j'ÃĐcouterai volontiers vos remarques et commentaires permettant de l'amÃĐliorer. ParticuliÃĻrement celles d'un debutant.
(Le systeme de commentaires en bas de page est là pour ca)
Sommaire
- Structure d'un code en C
- Les variables
- Un exemple...
- La Compilation
- Conditions et boucles
- OpÃĐrateurs de calcul et incrÃĐmentations
- Afficher des variables
- Les tableaux
- Les pointeurs
- Les chaÃŪnes de caractÃĻres
- La rÃĐcursivitÃĐ
- Manipulation de fichiers
- Les fichiers headers, les includes, les defines et les macros
Chapitre I
Chapitre II
Chapitre III
Chapitre I
Structure d'un code en C
- Du code C s'ÃĐcrit dans un fichier ayant pour extension .c. On le modifie avec n'importe quel ÃĐditeur de texte (emacs, vim, etc).
- Un code C s'exÃĐcute en suivant des instructions lignes par lignes dans des fonctions.
- Une fonction se compose de plusieurs partie :
- DÃĐclaration des variables utilisÃĐes
- Instructions
- Valeur retournÃĐe en fin de fonction (facultatif)
- La premiÃĻre fonction appelÃĐe est la fonction main. Il doit toujours y en avoir une dans un programme en C.
- Une fonction se dÃĐclare de la maniÃĻre suivante :
type_de_variable_retournee nom_fonction(type_argument1 nom_argument1, type_argument2 nom_argument2) { declaration1; declaration2; instruction1; instruction2; return (valeur_retournee); } - Une fonction peut appeler d'autres fonctions dans une instruction :
valeur_retournee = ma_fonction(argument1, argument2); - L'instruction "return" renvoie une valeur et cesse l'exÃĐcution de la fonction. Si on met des instructions aprÃĻs un return, celle-ci ne seront jamais exÃĐcutÃĐes.
- Une fonction doit Être dÃĐclarÃĐe avant d'Être appelÃĐe. Donc le main doit Être tout en bas du fichier.
Les variables
Les instructions utilisent des variables.
Ces variables ont des types permettant de dÃĐfinir leur taille (en octets).
Dans une variable, on ne peut que stocker un nombre, dont la limite infÃĐrieure et supÃĐrieure depend du type.
| Type | Nombre d'octets en mémoire | Nombre de bits en mémoire | Limite inférieure | Limite supérieure |
|---|---|---|---|---|
| char | 1 octet | 8 bits | - 128 | 127 |
| unsigned char | 1 octet | 8 bits | 0 | 255 |
| short | 2 octets | 8 x 2 = 16 bits | - 32 768 | 32 767 |
| unsigned short | 2 octets | 8 x 2 = 16 bits | 0 | 65 535 |
| int | 4 octets | 8 x 4 = 32 bits | - 2 147 483 648 | 2 147 483 647 |
| unsigned int | 4 octets | 8 x 4 = 32 bits | 0 | 4 294 967 295 |
| long | 4 octets | 8 x 4 = 32 bits | -2 147 483 648 | 2 147 483 647 |
| unsigned long | 4 octets | 8 x 4 = 32 bits | 0 | 4 294 967 295 |
| float | 4 octets | 8 x 4 = 32 bits | -3.4 x 10-38 | 3.4 x 1038 |
| double | 8 octets | 8 x 8 = 64 bits | -1.7 x 10-308 | 1.7 x 10308 |
| long double | 12 octets | 8 x 12 = 96 bits | -3.4 x 10-4932 | 3.4 x 104932 |
- Les char, short, int, long et leurs unsigned respectifs ne peuvent contenir que des entiers (2, 6, 42, 254, ...).
- Les float, double et long double peuvent contenir des nombres à virgule flottante (2.0, 6.21, 42.5694, -3.457, ...).
Le mot-clÃĐ void signifie l'absence de variable, par exemple, si une fonction ne renvoie rien ou si elle ne prend pas de paramÃĻtre.
Il existe des types prÃĐ-definis qui portent un nom permettant de connaitre leurs rÃīles.
Par exemple, size_t contient la taille d'un tableau (voir plus tard ce qu'est un tableau.)
ssize_t servira à parcourir un tableau.Pour utiliser une variable, on doit la dÃĐclarer en lui donnant un nom :
Dans une fonction, on dÃĐclare toutes les variables avant des les utiliser.type nom;
Les noms de fonctions ne doivent comporter que des lettres minuscules, des chiffres et des underscore ("_").
Ils doivent Être en anglais et explicites. GrÃĒce au nom de la variable, on doit comprendre ce qu'elle contient, à quoi elle sert dans le programme.
Le nom de variable i est souvent utilisÃĐ pour un compteur.- Les variables sont internes aux fonctions. Une variable dÃĐclarÃĐe dans une fonction n'existe nulle part ailleurs que dans celle-ci.
- Il est possible de dÃĐclarer des variables dites globales en les dÃĐclarant en dehors de toute fonction. Ce n'est pas recommandÃĐ, il vaut mieux les ÃĐviter autant que possible.
Un exemple...
... vaut mieux qu'un long discours !
int subtraction(int a, int b)
{
int result;
result = a - b;
return (result);
}
int main(void)
{
int i;
i = 3;
i = i + 5;
i = subtraction(i, 2);
return (0);
}
- Le programme commence son execution par la fonction main (elle ne prend aucun paramÃĻtre).
- Dans celle-ci, on dÃĐclare une variable de type int et de nom "i".
- On assigne ensuite une valeur à la variable i grace au "=".
--> i = 3. - L'instruction suivante utilise la valeur de i (3) et lui ajoute 5. Elle met ensuite ce rÃĐsultat dans i, ce qui ÃĐcrase son ancienne valeur.
--> i = 8. - L'instruction suivante appelle une fonction à laquelle elle donne deux arguments : i (8) et 2.
- On entre alors dans la fonction substraction. On voit qu'elle prend en paramÃĻtre 2 arguments de type int (a et b). Ca tombe bien, c'est ce qu'on lui a envoyÃĐ lors de l'appel !
--> a = 8 et b = 2. - On dÃĐclare ensuite une nouvelle variable de type int nomme "result".
--> a = 8, b = 2 et result = valeur inconnue (/!\ pas forcement = 0) - On effectue le calcul de a - b, c'est a dire 8 - 2, et on met cette valeur dans "result".
--> a = 8, b = 2 et result = 6 - L'instruction return renvoie la valeur de result et on retourne dans la fonction main.
- La valeur que la fonction a renvoyÃĐ est placee dans i.
--> i = 6. (a, b et result n'existe plus : ils ÃĐtaient propres à la fonction substraction). - La fonction main a alors terminÃĐ ses instructions et fait donc la derniÃĻre instruction qui retourne une valeur.
La valeur 0 signifie que l'exÃĐcution du programme s'est bien passÃĐe. Une autre valeur signifie qu'il y a eu une erreur.
UP
La Compilation
On compile avec gcc (alias cc).
Le compilateur gÃĐnÃĻre alors un fichier (executable) a.out.
Il est possible de modifier le nom du fichier grace a l'option -o
gcc -o nom_executable mon_code.c
S'il y a une ou plusieurs erreurs, elles seront affichÃĐes et la compilation s'arrÊtera.
Cependant, certaines "erreurs" peuvent ne pas empÊcher la compilation, on les appelle les Warnings.
Il est malgrÃĐ tout trÃĻs important de corriger ces petites erreurs car la plupart du temps, elle perturberont le fonctionnement normal du programme.
Pour afficher plus de Warnings, il est possible (et conseillÃĐ) d'ajouter des options (dites flags de compilation) :
- -w : DÃĐsactive tout les warnings (dÃĐconseillÃĐ)
- -Wextra : Affiche encore plus de warnings (dÃĐtails)
- -Wall : Affiche plus de warnings (dÃĐtails)
- -Werror : ConsidÃĻre les warnings comme des erreurs et cesse la compilation
- -ansi : Affiche des warnings en cas de non respect de la norme ISO C90
Il est aussi possible de demander au compilateur d'effectuer (ou pas) des optimisations :
- -O0 : DÃĐsactive toutes les optimisations
- -O1 : Optimisation de niveau 1 (dÃĐtails)
- -O2 : Optimisation de niveau 2 (dÃĐtails)
- -O3 : Optimisation de niveau 3 (details)
On peut compiler plusieurs fichiers C pour un meme programme.
Exemple de compilation :
gcc -O0 -Wall -Wextra -Werror -ansi -o mon_executable mon_code.c
Une fois que le programme est compilÃĐ, on peut le lancer pour voir ce qu'il fait :
./mon_executable
Conditions et boucles
-
On peut demander à un programme de n'effectuer une action que dans un cas prÃĐcis.
Pour cela, on utilise la construction if.
On peut aussi lui demander de faire autre chose dans un autre cas avec else if. (facultatif)
Puis, faire autre chose si aucun cas propose prÃĐcÃĐdemment ne correspond grace à else. (facultatif)if ( condition 1 ) { action; } else if ( condition 2 ) { action; } else { action; }
-
On peut demander a notre programme d'ÃĐxecuter une action tant qu'une condition est respectÃĐe grace à la construction while.
Il faudra alors faire attention à ce que la condition ne soit pas toujours respectÃĐe, car si c'est le cas, la boucle ne s'arrÊtera jamais. On appelle ca une boucle infinie.
while ( condition ) { action; action; } -
Une condition se construit de la maniÃĻre suivante :
Francais Symbole Exemple ÃĐgal == (n == 2) diffÃĐrent de != (i != 0) supÃĐrieur à > (j > 5) supÃĐrieur ou ÃĐgal à >= (k >= 4) infÃĐrieur à < (count < 2) infÃĐrieur ou ÃĐgal à <= (plop <= 3) -
On peut demander à ce que plusieurs conditions soient prises en compte.
Francais Symbole Exemple ET
Les deux conditions doivent Être vÃĐrifiÃĐes&& ((n == 3) && (j != 5)) OU
Au moins une condition doit Être vÃĐrifÃĐe|| ((substraction(5, 3) < 1) || (n <= 7)) OU exclusif
Une condition des deux conditions doit Être respectÃĐe, mais pas les deux^ ((i < 3) ^ (function(d) == 6)) condition ne doit pas etre vÃĐrifiÃĐe ! (!(k == 5)) - S'il n'y a qu'une seule action, on peut se passer des accolades :
if (i == 5) i = 6; else i = 5;
- Si on a besoin d'un if et d'un else (pas de else if), on peut utiliser un ternaire :
Cet exemple aura le meme comportement que celui ci-dessus :
(condition ? action-si-condition-respectee : action-si-condition-non-respectee);
(i == 5 ? i = 6 : i = 5);
- Il est possible d'utiliser la valeur de retour d'une fonction directement dans une condition :
if (subtraction(3, 5) != -2) return (-1); - On peut mÊme faire des calculs directement dans la condition :
if ((n + 1) == 3) - En fait, le systÃĻme de condition en C fonctionne comme un boolÃĐen. Le resultat final sera soit faux (= 0), soit vrai (toute autre valeur).
Ainsi, il est possible de remplacer (a == 0) par (!a) et remplacer (a != 0) par (a). - Exemple :
a = 1; b = 3; ((((a > 3) || (b > a)) && (a)) ^ (b == 3))- Comme pour un calcul de maths habituel, on commence par regarder ce qui se trouve à l'intÃĐrieur des parentheses les plus profondes.
On commence donc par (a > 3).
a = 1 et 1 n'est pas supÃĐrieur a 3.
La condition est donc fausse.((((FAUX) || (b > a)) && (a)) ^ (b == 3))
- Le sÃĐparateur est un || (OU).
Donc si l'instruction de droite est vraie, alors le tout est vrai.
Si l'instruction de gauche avait ÃĐtÃĐ vraie, alors on aurait pas eu besoin de regarder l'instruction de droite, puisqu'il faut qu'au moins une soit vraie pour que le tout soit vrai.
b = 3 et a = 1. (3 > 1) est bien vrai. On peut donc remplacer :
((((FAUX) || (VRAI)) && (a)) ^ (b == 3)) ((( VRAI ) && (a)) ^ (b == 3))
- Le prochain sÃĐparateur est un && (ET).
Les deux conditions doivent Être vraies, donc on doit aussi regarder celle de droite.
a n'est pas ÃĐgal a 0, donc a existe.
La condition est donc vraie.
(((VRAI) && (VRAI)) ^ (b == 3)) (( VRAI ) ^ (b == 3))
- Le sÃĐparateur est un ^ (Ou exclusif).
Il faut donc que l'une des deux conditions soit vÃĐrifiÃĐe, mais pas l'autre.
La condition de gauche est vraie, donc la condition de droite doit Être fausse pour que le tout soit vrai.
b = 3 donc (3 == 3) est vrai.
Les deux sont vraies, donc le tout est faux.((VRAI) ^ (VRAI)) ( FAUX )
- Comme pour un calcul de maths habituel, on commence par regarder ce qui se trouve à l'intÃĐrieur des parentheses les plus profondes.
OpÃĐrateurs de calcul et incrÃĐmentations
- Les opÃĐrateurs de calculs sont ceux habituels :
- + : addition
- - : soustraction
- * : multiplication
- / : division
- % : modulo (qu'est-ce que c'est ?)
- Une instruction de calcul peut donner une nouvelle valeur à une variable en utilisant la valeur de celle-ci.
Dans ces cas-là , il est possible d'utiliser des opÃĐrateurs d'affectations (=) effectuant un calcul sur la variable.
i = i + 3;
donnera le mÊme rÃĐsultat que la ligne prÃĐcÃĐdente.i += 3;
-
Le calcul sur la variable est effectuÃĐ en dernier, donc ici, on calculera (2 * 6) + i.
i += 2 * 6;
- Ces opÃĐrateurs d'affectations spÃĐciaux fonctionnent aussi avec les autres opÃĐrateurs de calculs :
- += : addition
- -= : soustraction
- *= : multiplication
- /= : division
- %= : modulo
- Si l'on souhaite ajouter 1 a notre variable, il existe une syntaxe spÃĐciale d'incrÃĐmentation :
- La post-incrementation : variable++
On fait l'action, puis on incrÃĐmente.
- La pre-incrementation : ++variable
On incrÃĐmente, puis on fait l'action.
- Exemple :
i = 1; if ((i++ == 2) || (++i == 3)) i -= 2;- (i++ == 2).
C'est une post-incrÃĐmentation.
On va donc utiliser la valeur actuelle de i (1) pour faire la vÃĐrification.
---> i = 1;
1 n'est pas ÃĐgal a 2. C'est donc FAUX.
Une fois la vÃĐrification faite, on incrÃĐmente.
---> i = 2; - (++i == 2).
C'est une prÃĐ-incrementation.
On va donc incrÃĐmenter i avant de faire la verification.
---> i = 3;
On fait maintenant la vÃĐrification.
i (3) est bien egal à 3. C'est donc VRAI.
- La condition est donc vraie, et i vaut 3 a la fin de la vÃĐrification de la condition.
- Comme la condition est vraie, on fait le calcul. On enlÃĻve 2 Ã i (3), ce qui donne 1.
- (i++ == 2).
- Il existe une syntaxe identique au mÊme comportement pour la dÃĐcrÃĐmentation de 1.
i-- est une post-decrementation
--i est une pre-decrementation.
- La post-incrementation : variable++
- On peut utiliser ces syntaxes d'[in-de]crementation pour remplacer une ligne de calcul.
peut alors etre remplacÃĐ par :i = i + 1;
(La prÃĐ-incrementation est recommandÃĐ dans ces cas-la) (Pourquoi ?)++i;
Afficher des variables
Pour donner à une variable comme valeur une lettre, on a deux solutions :
- Lui donner sa valeur de maniÃĻre claire en utilisant des quotes :
char c; c = 'a';
- Donner sa valeur ASCII :
char c; c = 97;
- 48 - 57 | '0' - '9'
- 65 - 90 | 'A' - 'Z'
- 97 - 122 | 'a' - 'z'
D'autres caractÃĻres non visibles mais qui peuvent etre utiles :
- 00 | '\0' | NULL, 0
- 07 | '\a' | bell, bip sonore
- 08 | '\b' | backspace
- 09 | '\t' | Tabulation
- 10 | '\n' | Retour a la ligne
- 11 | '\v' | Tabulation verticale
- 13 | '\r' | Revient au debut de la ligne
Pour afficher une lettre, on va utiliser cette petite fonction :
#include <unistd.h> void print_char(char c) { write(STDOUT_FILENO, &c, sizeof(c)); }
Ce petit programme va afficher la lettre 'p' suivie d'un retour à la ligne et finir le programme en indiquant qu'il est rÃĐussi :
int main(void)
{
print_char('p');
print_char('\n');
return (0);
}
Chapitre II
Les tableaux
- Si l'on a besoin de stocker plusieurs variables, on peut utiliser un tableau.
Un tableau, c'est plusieurs variables d'un mÊme type les unes à la suite des autres.
On peut dÃĐclarer un tableau ainsi :
Les cases du tableau commencent a 0.type nom[nombre_de_cases];
Ici, la case tab[3] n'existe pas, ni toutes celles d'aprÃĻs.int tab[3]; tab[0] = 1; tab[1] = 76; tab[2] = 5;
- Pour ÃĐcrire plus qu'une lettre, mais ÃĐcrire un mot, les tableaux sont trÃĻs pratiques :
Par convention, on termine un mot par le caractÃĻre '\0' qui sert a repÃĐrer la fin du mot.
char str[4]; str[0] = 'L'; str[1] = 'o'; str[2] = 'L'; str[3] = '\0';
Les pointeurs
- Chaque variable, pour Être utilisÃĐe, doit Être stockÃĐe quelque part dans la mÃĐmoire.
On dit que cette variable se trouve a une adresse en mÃĐmoire.
Cette adresse est un numero que l'on exprime en gÃĐnÃĐral en hexadecimal (type 0x7f6a8d). - Un pointeur est une variable qui contient l'adresse d'une autre variable.
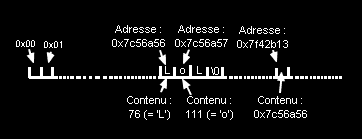
- Sur le schema, les petites cases reprÃĐsentent les variables stockÃĐes dans la mÃĐmoire.
Notre tableau de tout a l'heure y est reprÃĐsentÃĐ.
En dessous, le contenu des cases du tableau, et au dessus, l'adresse ou elles sont stockÃĐes.
A un autre endroit dans la mÃĐmoire, une autre variable est stockÃĐe.
Elle a pour contenu l'adresse de la premiÃĻre case du tableau.
-
Dans la partie dÃĐclarations d'une fonction :
- On dÃĐclare un pointeur en indiquant comme type celui vers lequel il pointe et en ajoutant une * devant le nom.
est un pointeur dont le contenu sera l'adresse d'une variable de type int.
int *pointer;
- On dÃĐclare un pointeur en indiquant comme type celui vers lequel il pointe et en ajoutant une * devant le nom.
-
Dans la partie instructions d'une fonction :
- On rÃĐcupÃĻre l'adresse d'une variable en ajoutant un & devant le nom de la variable.
- On rÃĐcupÃĻre ce qui se trouve à l'adresse contenue dans le pointeur en ajoutant une * devant le nom du pointeur.
On dit alors qu'on dÃĐrÃĐference un pointeur.
- Exemple :
char c; char *p; c = 'a'; print_char(c); p = &c; *p = 'z'; print_char(c); print_char(*p); print_char('\n');
- On dÃĐclare une variable de type char que l'on appelle c.
- On dÃĐclare un pointeur vers un char que l'on appelle p.
- On met la lettre 'a' (valeur ASCII 97) dans la variable c.
--> c = 97 ; p = valeur inconnue. - On affiche le contenu de la variable c.
- On rÃĐcupÃĻre l'adresse de la variable c et on la met dans le pointeur p.
--> c = 97 ; p = adresse de c (de type 0x75f5a). - On dÃĐrÃĐference le pointeur p pour modifier son contenu et y mettre la lettre z (valeur ASCII 122).
--> c = 122 ; p = adresse de c. - On affiche c. On voit qu'il contient bien la nouvelle valeur : 'z'.
- On dÃĐrÃĐference le pointeur p pour afficher le contenu de la variable vers laquelle il pointe. C'est le contenu de c, donc ca affiche la meme chose que prÃĐcÃĐdemment.
- On affiche un retour a la ligne, c'est toujours plus joli.
- Quand on dÃĐclare un tableau, on dÃĐclare en fait un pointeur vers la premiere case du tableau.
- ConcrÃĻtement, ces deux lignes sont ÃĐquivalantes :
tab[0] = 3; *tab = 3;
- On peut demander à un pointeur d'Être vide. On lui donne alors la valeur NULL.
Les chaÃŪnes de caractÃĻres
On appelle une chaÃŪne de caractÃĻres un tableau de type char qui contient des lettres (leurs valeurs ASCII) et qui se termine par un '\0'.
On peut envoyer une chaine de caractere à une fonction en utilisant des double quotes (") "ma chaine de caracteres\n".Les simples quotes (‘) sont utilisÃĐes pour les caractÃĻres seuls.
La fonction à laquelle on aura envoye la chaÃŪne de caracteres grÃĒce à des doubles quotes prendra alors en paramÃĻtre un pointeur vers un char. C'est le pointeur vers la premiÃĻre case du tableau qui contient une chaÃŪne de caractÃĻres.
void print_string(char *string)
{
/* fonction qui affiche */
}
int main(void)
{
print_string("Le pays du 42");
return (0);
}Chapitre III
La rÃĐcursivitÃĐ
- Une fonction rÃĐcursive est une fonction qui s'appelle elle-mÊme.
- La rÃĐcursivitÃĐ peut s'utiliser en remplacement d'une boucle.
- Exemple :
Ces deux fonctions ont le mÊme comportement, mais l'une utilise une boucle et l'autre est rÃĐcursive.void print_c_while(int n) { int i; i = 0; while (i < n) { print_char('c'); ++i; } } void print_c_recursive(int n, int i) { if (i < n) { print_char('c'); print_c_recursive(n, ++i); } } int main(void) { print_c_while(10); print_char('\n'); print_c_recursive(10, 0); print_char('\n'); return (0); }
Manipulation de fichiers
- Pour lire et ÃĐcrire dans des fichiers, on utilise des filedescriptor (ou fd).
Ce sont des int qui contiennent un numÃĐro.
Ces "numÃĐros" indiquent quel est le fichier sur lequel on ÃĐcrit.
On n'attribue pas soi-mÊme ces nombres, ce sont des appels systÃĻme qui les gÃĻrent.
Certains nombres (fd) sont rÃĐservÃĐs :
- L'entrÃĐe standard (ou STDIN_FILENO) : en gÃĐnÃĐral ÃĐgal à zero, on l'associe souvent au clavier, sur lequel on va lire des informations. Quand j'entre une commande dans mon terminal, il va lire ce que j'ÃĐcris sur l'entrÃĐe standard.
- La sortie standard (ou STDOUT_FILENO) : en gÃĐnÃĐral ÃĐgal à un, c'est ce qui nous permet de lire des informations à l'ecran. Quand une commande ou un programme est exÃĐcutÃĐ, il affiche du contenu sur la sortie standard. C'est ce que faisait notre fonction print_char.
- La sortie d'erreur (ou STDERR_FILENO) : en gÃĐnÃĐral ÃĐgal à deux, elle a souvent le mÊme comportement que la sortie standard mais permet de diffÃĐrencier les messages de bon fonctionnement du programme à ceux qui apparaissent en cas d'erreur(s). Les erreurs et warnings de compilations sont par exemple affichÃĐs sur la sortie d'erreur.
- Les appels systÃĻme sont des fonctions qui renvoient une valeur.
Celle-ci doit absolument Être vÃĐrifiÃĐe.
En cas d'ÃĐchec, il se peut que la suite de l'exÃĐcution du programme soit perturbÃĐe, et il vaudra mieux, alors, en cas d'ÃĐchec, arrÊter le programme (en affichant un message d'erreur, par exemple). - Pour ÃĐcrire dans un fd, on utilise la fonction write.
Elle prend en paramÃĻtre le fd, une chaine de caractÃĻres et une taille.
Elle retourne le nombre de caractÃĻres ÃĐcrits (et -1 en cas d'ÃĐchec).
Lire le man 2 de write ! - Pour lire dans un fd, on utilise la fonction read.
Elle prend en paramÃĻtre le fd, un buffer (un tableau qui sert a stocker) et une taille.
Elle retourne le nombre de caractÃĻres lus.
Lire le man 2 de read ! - Pour ouvrir un fichier, c'est-Ã -dire associer un fd a un fichier dans lequel on pourra lire et ÃĐcrire, on utilise la fonction open.
Elle prend en paramÃĻtre le chemin du fichier et le type d'ouverture.
Les types d'ouvertures :- O_RDONLY : Lecture uniquement
- O_WRONLY : Ecriture uniquement
- O_RDWR : Lecture et ÃĐcriture
- O_CREAT : CrÃĐer un fichier qui n'existe pas
- O_TRUNC : Ecrase le fichier dans le cas ou on essaierai de crÃĐer un fichier qui existe dÃĐjÃ
- O_APPEND : Ecrit a la fin du fichier
Lire le man 2 de open ! - Le nombre de filedescriptor est limitÃĐ, donc il vaut mieux les ÃĐconomiser.
Il est donc extrÊmement important de "libÃĐrer" le numero filedescriptor correspondant à un fichier aussitÃīt que l'on n'a plus besoin de celui-ci.
Pour cela, on utilise l'appel systÃĻme close qui ferme un filedescriptor.
Elle prend en paramÃĻtre un filedescriptor et renvoie 0 en cas de rÃĐussite, -1 sinon. - Exemple : Lire sur l'entree standard, ÃĐcrire sur la sortie standard.
#include <unistd.h> #include <stdlib.h> void print_string_fd(int fd, char *string) { ssize_t i; int w; i = 0; while (string[i]) ++i; w = write(fd, string, i); if (w == -1) exit(EXIT_FAILURE); } void print_username(void) { char buffer[12]; int r; print_string_fd(STDOUT_FILENO, "Bonjour ! Quel est ton nom ? "); if ((r = read(STDIN_FILENO, buffer, 12)) == -1) { print_string_fd(STDERR_FILENO, "Il y a eu une erreur avec la fonction read.\n"); exit (EXIT_FAILURE); } buffer[r - 1] = '\0'; print_string_fd(STDOUT_FILENO, "Tu t'appelles "); print_string_fd(STDOUT_FILENO, buffer); print_string_fd(STDOUT_FILENO, ". Quel joli nom !\n"); }- La fonction print_string_fd a le mÊme comportement que la fonction print_string.
Elle prend en plus en parametre un fd, ce qui lui permet d'ecrire sur le fd que l'on souhaite.
Elle calcule aussi la taille de la chaÃŪne de caractÃĻres et n'utilise qu'une fois l'appel systÃĻme write.
Si l'appel systeme write ÃĐchoue, le programme est quittÃĐ grace à la fonction exit. - On lit sur l'entrÃĐe standard ce que l'utilisateur va ÃĐcrire.
Ce qui est lu est stockÃĐ dans un buffer.
Ce buffer est un tableau de 12 cases.
On va donc lire une taille de 12 pour ÃĐviter de dÃĐpasser la place qui nous est allouÃĐe.
On rÃĐcupÃĻre la valeur de retour de read pour deux raisons :- Pour vÃĐrifier que l'appel systÃĻme n'a pas ÃĐchouÃĐ.
- Pour connaÃŪtre la taille du mot.
S'il est plus court, le tableau buffer ne sera pas complÃĻtement rempli !
- Si l'appel systÃĻme ÃĐchoue, on affiche un message d'erreur sur la sortie d'erreur et on quitte le programme.
EXIT_FAILURE indique que le programme n'a pas rÃĐussi, EXIT_SUCCESS (= 0) indiquerai que le programme a quittÃĐ en ayant son comportement normal.
Rappel : Retourner la valeur 0 en fin de programme signifie que l'execution du programme s'est bien passÃĐ. Une autre valeur signifie qu'il y a eu une erreur. - L'appel systÃĻme read ne met pas de '\0' a la fin du mot qu'il a lu (puisqu'il ne lit pas que des mots, en fait).
Il faut donc le mettre soi-mÊme, car si on ne le fait pas, notre fonction print_string_fd ne saura quand s'arrÊter.
- La fonction print_string_fd a le mÊme comportement que la fonction print_string.
- Exemple : Lire dans un fichier, ÃĐcrire dans un nouveau fichier
void readfile(void) { int fd; int new_file; int r; char buff[20]; if ((fd = open("file.txt", O_RDONLY)) == -1) { print_string_fd(STDERR_FILENO, "Open n'a pas reussi. \ Sans doute parce que le fichier n'existe pas ou n'a pas les \ droits en lecture.\n"); exit(EXIT_FAILURE); } if ((new_file = open("new_file.txt", O_WRONLY|O_CREAT|O_TRUNC)) == -1) { print_string_fd(STDERR_FILENO, "Erreur lors de la creation du nouveau fichier.\n"); exit(EXIT_FAILURE); } while ((r = read(fd, buff, 20)) > 0) write(new_file, buff, r); close(fd); close(new_file); }
- On commence par ouvrir le fichier de dÃĐpart, en lecture seule. En cas d'ÃĐchec, on quitte.
- On crÃĐÃĐ ensuite un nouveau fichier. Si le fichier existe dÃĐjà , on l'ÃĐcrase. On compte ÃĐcrire seulement dedans.
- On lit dans le fichier puis on ÃĐcrit dans le nouveau fichier, et ce, tant qu'il y a des choses a lire (tant que read n'a pas renvoyÃĐ 0 ou une erreur.)
- On a termine avec les deux fichiers, on ferme les filedescriptors.
- En lançant ce programme, on se rend compte que s'il n'y a pas eu d'erreur, rien ne s'affiche. C'est normal : On n'a rien ÃĐcrit sur la sortie standard, on a ÃĐcrit dans un fichier. En ouvrant le fichier new_file.txt, on voit qu'il contient la mÊme chose que file.txt.
- Pourquoi n'a't-on pas ajoute de '\0' a la fin du buffer lu ? On ne lit pas forcement des chaÃŪnes de caractÃĻres, on peut aussi lire du binaire. On utilise directement write en lui donnant un nombre de caractÃĻres à afficher. A aucun moment on ne parcoure le buffer à la recherche d'un '\0' indiquant la fin. Et pour cause : si on lit du binaire, par exemple, un '\0' pourra se trouver au milieu mais ne voudra pas dire que le fichier est terminÃĐ !
Les fichiers headers, les includes, les defines et les macros
- Il existe des fichiers a l'extension .h que l'on appelle les fichiers headers qui contiennent diverses informations pour utiliser des fonctions en C.
- On a vu par exemple que l'on ne pouvait pas utiliser la fonction write sans ajouter cette ligne en dÃĐbut de fichier :
#include <unistd.h>
- La prÃĐsence des < > indique que le fichier se trouve dans le dossier des headers standard. En gÃĐnÃĐral, c'est /usr/include. On peut donc voir le contenu du fichier pour mieux comprendre.
- Si on met des " ", cela signifie que le fichier header est dans le dossier courant (ou celui spÃĐcifiÃĐ Ã la compilation grace a -I).
- En gÃĐnÃĐral, on aura un fichier .h par fichier .c.
- Cela permet de compiler avec plusieurs fichiers sÃĐparÃĐs.
- Le mieux est d'avoir un fichier .c par fonction.
- Les fichiers headers contiennent des prototypes de fonction.
Un prototype de fonction :Ne pas oublier le ; a la fin !type_de_variable_retournee nom_fonction(type_argument1, type_argument2);
- Les fichiers headers contiennent aussi des defines.
Ce sont des valeurs qui sont remplacÃĐes dans le code avant la compilation.#define NOM VALEUR
On met leurs noms en majuscule de façon à la diffÃĐrencier des noms de variables.
TrÃĻs utile lorsque que l'on utilise plusieurs fois une valeur : si on a besoin de la changer, on ne le fera qu'une seule fois.
C'est toujours bien d'en utiliser, mÊme si la valeur n'est utilisÃĐe qu'une fois, dans le cas oÃđ elle peut Être modifiÃĐe.
Ca marche aussi avec des chaÃŪnes de caractÃĻres ! - Exemple :
Le fichier test_read.c :Le fichier test_read.h :#include "test_read.h" int test_read(int fd) { char buffer[BUFF_SIZE]; if (read(fd, buffer, BUFF_SIZE) == -1) { print_string_fd(STDERR_FILENO, MSG_READ_ERR); return (FALSE); } return (TRUE); } int main(void) { return (test_read(STDIN_FILENO) ? EXIT_SUCCESS : EXIT_FAILURE); }#ifndef TEST_READ_H_ # define TEST_READ_H_ # include <stdlib.h> # include <unistd.h> # define FALSE 0 # define TRUE !FALSE # define BUFF_SIZE 1024 # define MSG_READ_ERR "Error: read\n" int test_read(int); #endif /* !TEST_READ_H_ */- Vous vous en serez doutÃĐ : STDOUT_FILENO, EXIT_SUCCESS, etc sont des defines !
Vous pouvez aller voir les dÃĐclarations de STDOUT_FILENO anc co dans /usr/include/unistd.h.
Vous pouvez aller voir les dÃĐclarations de EXIT_SUCCESS anc co dans /usr/include/stdlib.h. - Le fichier .c inclut son fichier .h associe, et rien d'autre.
Les defines, includes, macros, prototypes se trouvent dans le fichier .h. - On peut faire des if et des else dans les .h !
- #if EXPRESSION = si EXPRESSION est vrai (les expressions sont a peu prÃĻs ÃĐquivalante au C)
- #elif EXPRESSION = equivalent au else if en C
- #else = equivalent au else en C
- #ifdef NOM_DEFINE = si NOM_DEFINE a ÃĐtÃĐ dÃĐclarÃĐ
- #ifndef NOM_DEFINE = si NOM_DEFINE n'a pas ÃĐtÃĐ dÃĐclarÃĐ
- #endif = Ã la fin des vÃĐrifications
En fait, on dÃĐfinit toutes nos dÃĐclarations dans une dÃĐfinition appelÃĐe TEST_READ_H_.
Mais avant de le faire, on vÃĐrifie si cette grosse dÃĐfinition n'a pas ÃĐtÃĐ faite auparavant, si, par exemple, j'avais inclus 2 fois le fichier test_read_h.
Il est extrÊmement important de protÃĐger tout les fichiers headers contre la multi-inclusion !
- Vous vous en serez doutÃĐ : STDOUT_FILENO, EXIT_SUCCESS, etc sont des defines !
- Les macros sont tout simplement des defines qui ont pour particularitÃĐ de contenir des morceaux de code et de prendre des valeurs (ou variables) en paramÃĻtre.
En gÃĐnÃĐral, on y met des ternaires.
Cette macro prend en paramÃĻtre une valeur (peu importe le type) et renvoie TRUE si elle est nÃĐgative, FALSE sinon. (TRUE et FALSE dÃĐfinie plus tot)#define IS_NEGATIVE(value) (value < 0 ? TRUE : FALSE)
UP